mysql中用count(id)或count(*)查询表记录总数时间超长怎么办?
 Admin
Admin
发布:2017-06-18 23:55:14 分类:群聊整理
群友问题:
mysql中单表记录行数超过一百万条,使用count(id)或count(*)查询表记录总数时间需要13分钟多,怎么办?表已经设置了主键和索引
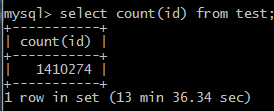
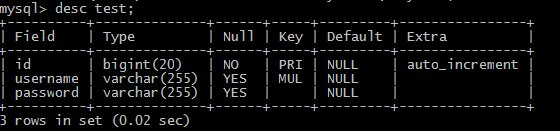
解决办法:
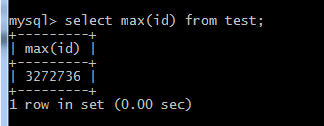
使用max()函数直接取出id列的最大值,0秒完成。请自行脑补适用场景,需要考虑是否逻辑删除物理删除分区分表主键索引引擎服务器配置等多方面因素。
- Admin Time:2017-06-18 23:58:40如果只要得到表的数据量,如果只是一个近似值也可以执行下面的语句:
explain select PK from tableName;里面的rows就是个近似值
- Admin Time:2017-06-19 00:02:11
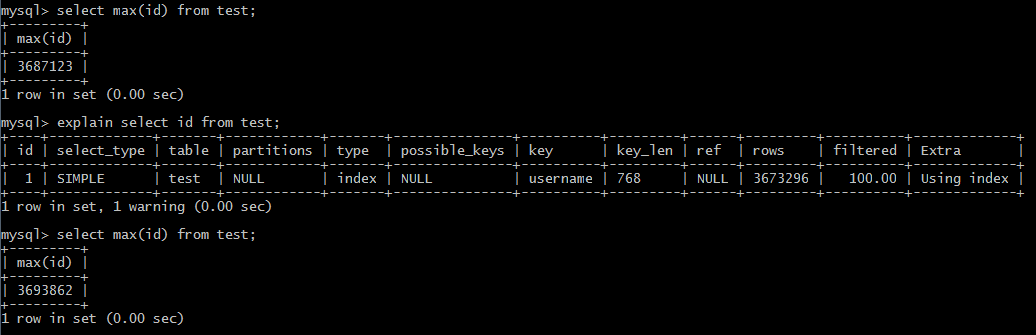
- Admin Time:2017-06-19 09:09:30一百多万条记录统计总数需要13多分钟,是很不正常的,说明表设计可能有问题。max(id) 函数取的是id列最大值,这个只能代表递增到了多少行,其中的删除操作没计算在内。
如果用 select max(id) from test;使用SQL语句:explain select id from test;从所得的结果中取出rows的值,也是一种值得考虑的办法。使用explain语句去查看分析结果 (仅供参考)如explain select * from test1 where id=1;会出现:id selecttype table type possible_keys key key_len ref rows extra各列。其中,table输出的行所引用的表type=const表示通过索引一次就找到了;key=primary表示使用了主键;
type=all表示为全表扫描;type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL 一般来说,得保证查询至少达到range级别,最好能达到ref。key=null表示没用到索引。显示MySQL实际决定使用的键。如果没有索引被选择,键是NULL。key_len,显示MySQL决定使用的键长度。如果键是NULL,长度就是NULL。文档提示特别注意这个值可以得出一个多重主键里mysql实际使用了哪一部分。possible_keys,指出MySQL能使用哪个索引在该表中找到行。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引。type=ref,因为这时认为是多个匹配行,在联合查询中,一般为REF。ref显示哪个字段或常数与key一起被使用。rows这个数表示mysql要遍历多少数据才能找到,在innodb上是不准确的。Extra,如果是Only index,这意味着信息只用索引树中的信息检索出的,这比扫描整个表要快。如果是where used,就是使用上了where限制。如果是impossible where 表示用不着where,一般就是没查出来啥。如果此信息显示Using filesort或者Using temporary的话会很吃力,WHERE和ORDER BY的索引经常无法兼顾,如果按照WHERE来确定索引,那么在ORDER BY时,就必然会引起Using filesort,这就要看是先过滤再排序划算,还是先排序再过滤划算。
- [ 发单/接单 ]
- ● 换IP投票软件
- ● PC蛋蛋自动挂机投注
- ● 新浪微博发微博显示尾巴的方法,比如显示来自iphone 7
- ● 百度文库批量自动上传软件
- ● 一点资讯app刷阅读量/评论/收藏/订阅功能/手机号注册
- ● 定做一个阿迪达斯官网注册器(需要破点击文字式验证码)
- ● 定制人人网自动注册/修改资料/采集/私聊软件
- ● 酷狗繁星直播网页协yi
- ● YY多功能刷订阅刷粉丝
- ● 滑块验证码本地识别
- ● 狼人杀POST QQ登录注册 获取金币数量
- ● 做个贴吧发发帖的软件懂的来
- ● 今日头条账号保存cookie
- ● 抖音粉丝软件定做,只要粉丝
- ● 百家号自媒体发文软件定制
- ● 哔哩哔哩播放量
- ● 读取TB某个商品上架时间和相关信息
- ● 网易博客软件定制
- ● 定制天涯论坛发帖软件
- ● 定制今日头条批量自动发私信软件
- [ 站内搜索 ]
- [ 最近热帖 ]
- 万能助手 -- 扩展库大全集 13751
- 用aardio创建web工程图文讲解(1) 12839
- 电脑编程入门自学:Fiddler https 抓包时提示创建根证书不成功问题彻底解决(https插件dll方式) 11742
- aardio绘图演示 11412
- 通过chrome.dll中间件控制外部chrome浏览器 10124
- 我常用的aardio技巧 9772
- 《边学C语言边赚钱——简码编程入门教程》系列集合 9616
- aardio使用http或whttp进行get/post请求时经常cookies失效怎么办?__电脑计算机编程入门教程自学 9322
- [源码下载]简码视频加密解密播放工具个人版v1.0发布,永久免费开源的知识变现神器 8557
- python人工智能爬虫系列:怎么查看python版本_电脑计算机编程入门教程自学 8048
- 编程入门教程:aardio批量上传文件并显示进度条 7883
- aardio调用nodejs的ws模块做一个简单的聊天通信示例 7037
- 电脑计算机编程入门教程自学:原生JavaScript判断字符是否为A-Za-z英文字母 6908
- 电脑计算机编程入门教程自学:腾讯tx或极验geetest滑块按住拖动完成拼图验证成功破解思路及源码 6501
- 乐玩插件AARDIO调用 6085
- [ 近期热答 ]
- 电脑计算机编程入门教程自学:什么是buffer缓冲区? 1
- aardio_代码编辑框书签管理器开源 1
- aardio_怎么用ide库从代码编辑框中取出指定行的源码? 1
- aardio_codepage代码页编码乱码暴力猜解工具 1
- aardio内嵌echarts图表添加鼠标事件响应功能 2
- aardio列表框listbox_模糊查找和精确查找 1
- 8亿QQ绑定手机泄露:通过腾讯QQ号查询QQ绑定的手机号码漏洞! 1
- carl listviewex调用例子----------源码搬运工 2
- Aardio内嵌Electron浏览框怎么正确添加启动参数? 1
- Aardio取汉字的字节数或字符数 1
- 怎么实现mssql图片数据的读写 2
- aardio_从49个数字里选六个和值为150的不重复的数字 1
- 在嵌入wps的时候,多了一个 透明的边框,这个怎么消除它 1
- 万能助手入门帮助教程:学会科学地管理工作文件 1
- Aaardio开发内嵌Electron浏览框放服务器上无法下载组件的解决办法 1